metrics EC484_Econometrics_Analysis
Motivation
In econometrics, we often want to understand the relationship between two variables, say and . While parametric methods like linear regression assume a specific functional form for this relationship, nonparametric methods allow us to estimate it without such assumptions. This is particularly useful when the true relationship is complex or unknown. The idea is that we don’t assume the form of the relationship between and , but instead let the data speak for itself.
Basic Idea
Consider an i.i.d. sample with pdf . At point , we want to estimate and the value of pdf at , but not using the parametric form to do so.
A Quick Review of CDF/PDF
See more on Cumulative Distribution Function
The CDF is defined as:
While the PDF is defined as:
How to get PDF from CDF?
Consider a very small interval ( is really small!), we have:
We divided by on both sides:
The LHS is the approximation of the density, and the RHS is the definition of derivative. Thus, we have: when :
In the slides, we have:
The intuition behind the relationship between PDF and CDF is that the higher the value of PDF, the faster the CDF increases at that point, meaning that there are a lot of observations around that point.
Also the term can be estimated by:
The indicator function equals to 1 if is in the interval , and 0 otherwise. It’s just like a counter.
Generalization
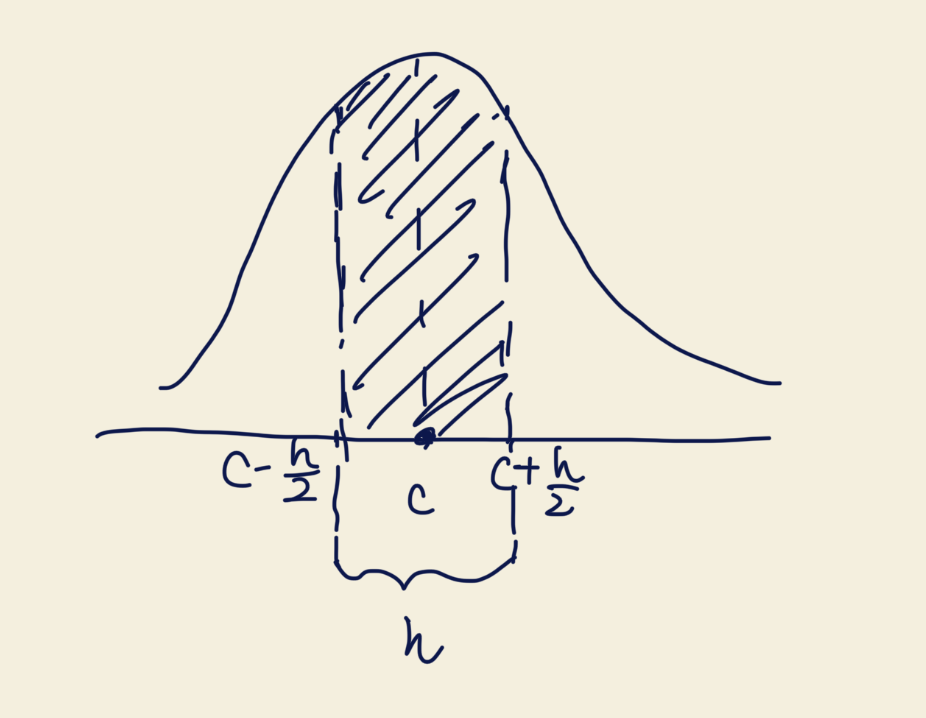
Recall that we have that , we can generalize it to:
Where is called the bandwidth. It controls the width of the interval around . A smaller means a narrower interval, which can capture more local details but may be noisier. A larger smooths out the estimate but may miss important features.
A graph to help understand:
Rewrite
Where . The meaning of is the relative distance between and , scaled by the bandwidth . Since we scale by , no matter how we choose , the interval always maps to in the space.
Kernel Density Estimator
The above estimator is called the Histogram Density Estimator. It is simple but has some drawbacks, such as being discontinuous and sensitive to the choice of bandwidth. We replace the indicator function with a smooth function called a kernel function , which satisfies:
Where is a kernel function that assigns weights to observations based on their distance from . Common choices for include:
- Uniform kernel
- Normal kernel
- Epanechnikov kernel
- Triangular kernel
It doesn’t matter which kernel function you choose, the results are often quite similar. The choice of bandwidth has a much larger impact on the estimate.
Properties: Mean, Variance, and Consistency
Mean
Note that:
From the definition of expectation, we have:
Let , then and . Thus:
Using Taylor expansion, we have:
Here, we have an extra term instead of because of the Lagrange form of the remainder in Taylor expansion. It’s new to me as well, and from
Claudeit suggests that it’s another representation to capture the error term more accurately. i.e. .
Formally, the Largrangian form of the Taylor Expansion is:
Where . In this form, we let .
Back to our derivation, we have:
Then we have:
Using the Condition of the Kernel Function:
- (The symmetric)
We have:
Focus on the last term, we have:
Simple Construction
We let the last term to be :
Thus we have:
The last step is to prove that as .
Why we need to do so? Because if , then we have , which means our estimator is asymptotically unbiased.
Recall that:
Our aim: prove that when ,
Since from our condition, we have that is continuous at . By the definition of continuity, for any , there exists a such that if , then .
In other words, as long as is closed to , then is closed to .
We know that because of the property of the kernel function: when . Thus, it is easy to have:
We pick , then we have:
Since , we have:
for all .
Now we are able to estimate :
Since is arbitrary, we have as .
Thus we have shown that as
Variance
The method is similar to the derivation of mean.
We recall that , and recall the definition of the variance:
Then we take the integral:
Similar to what we have done in the mean part, we let , then and . Thus:
For simplification, we denote:
where and .
For , using Taylor expansion, we have:
Thus we have:
Since (The symmetric), we have:
We could also follow the lecture slides where we let:
where .
And we could also show that as using the similar method in the mean part.
We skip the part of because the method is very similar. Finally we could have
Consistency
We finally could have:
Since convergence in mean square implies convergence in probability, we have: